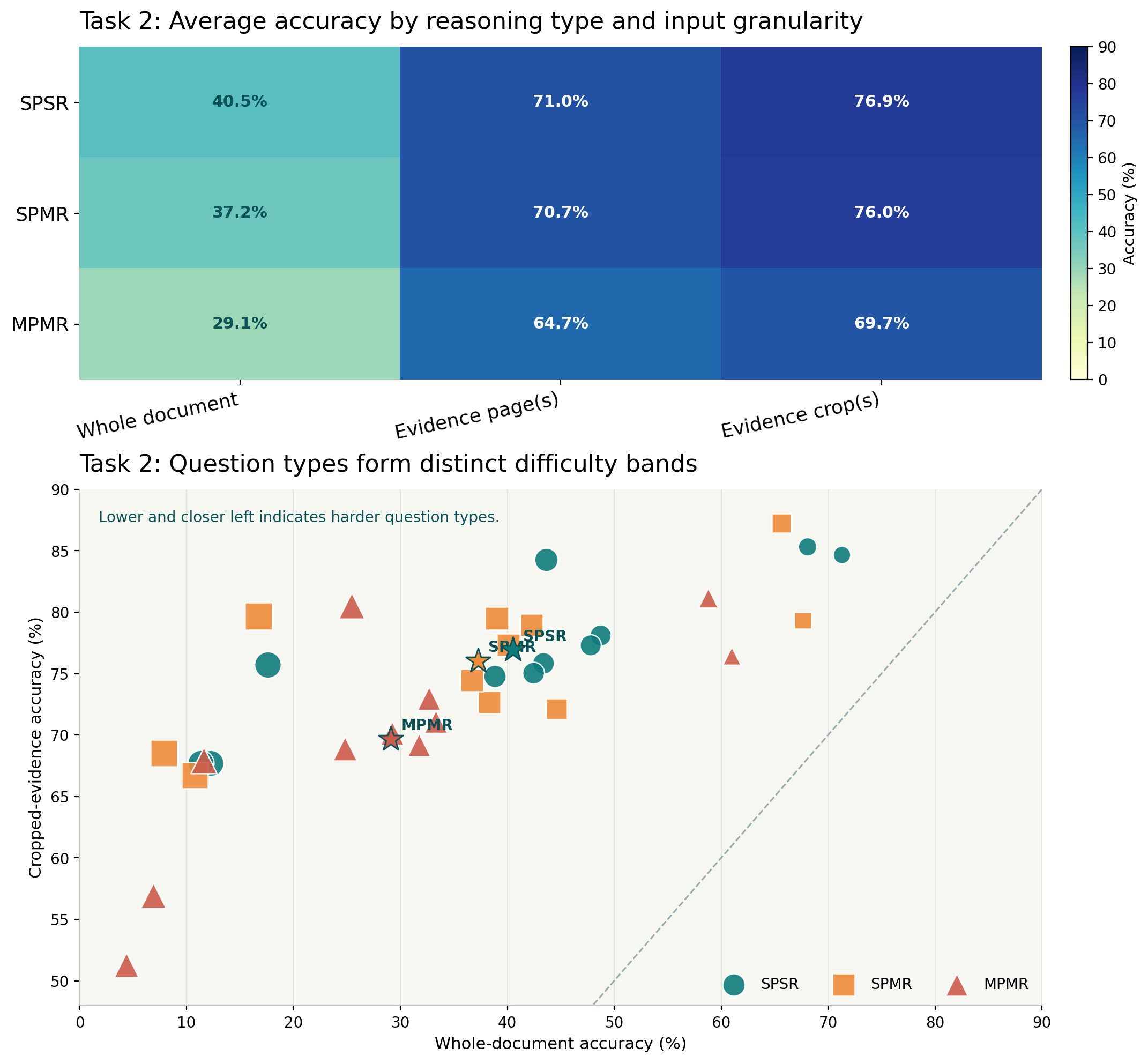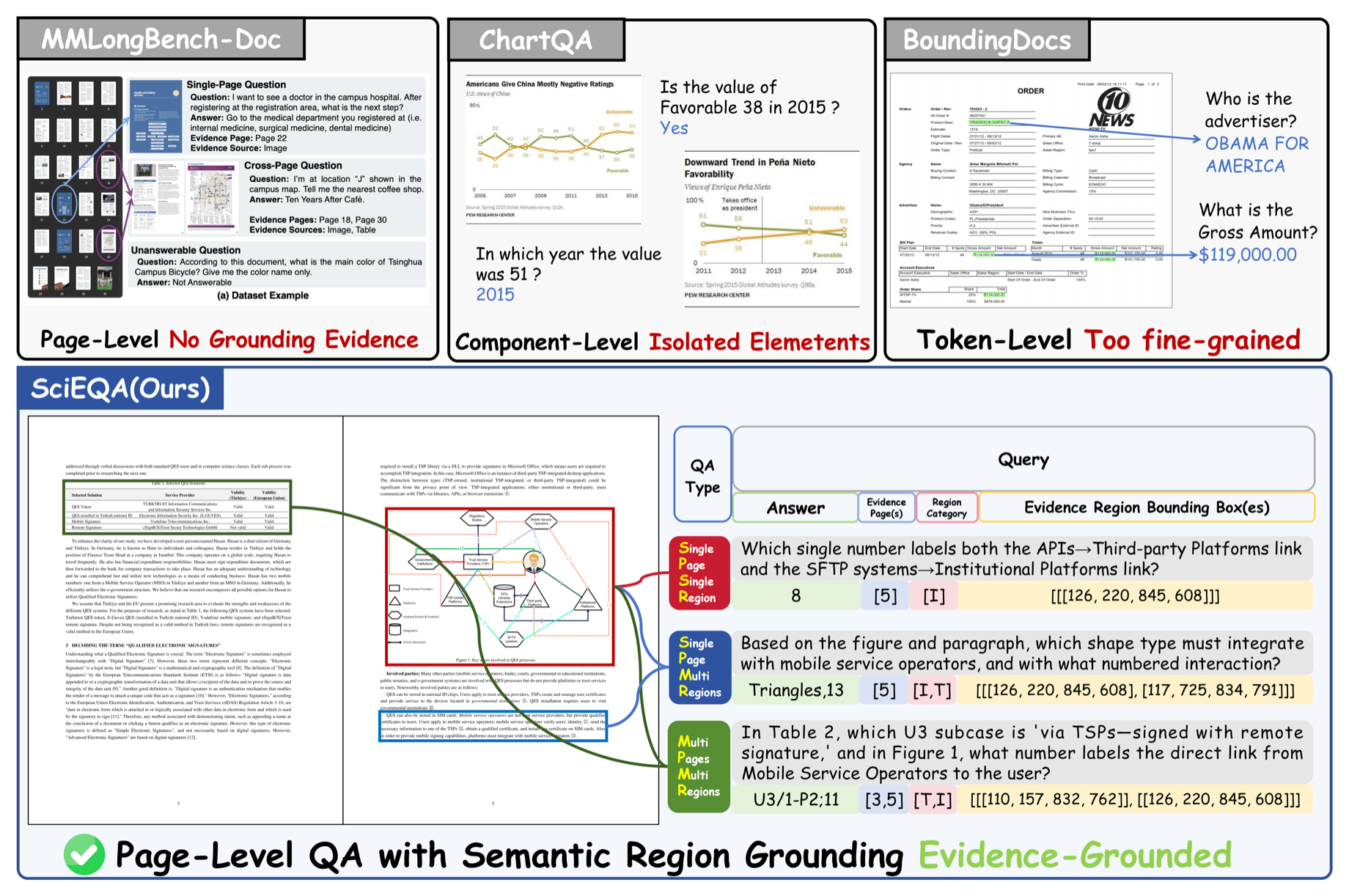
Human annotated
SciEGQA Benchmark
SciEGQA Benchmark
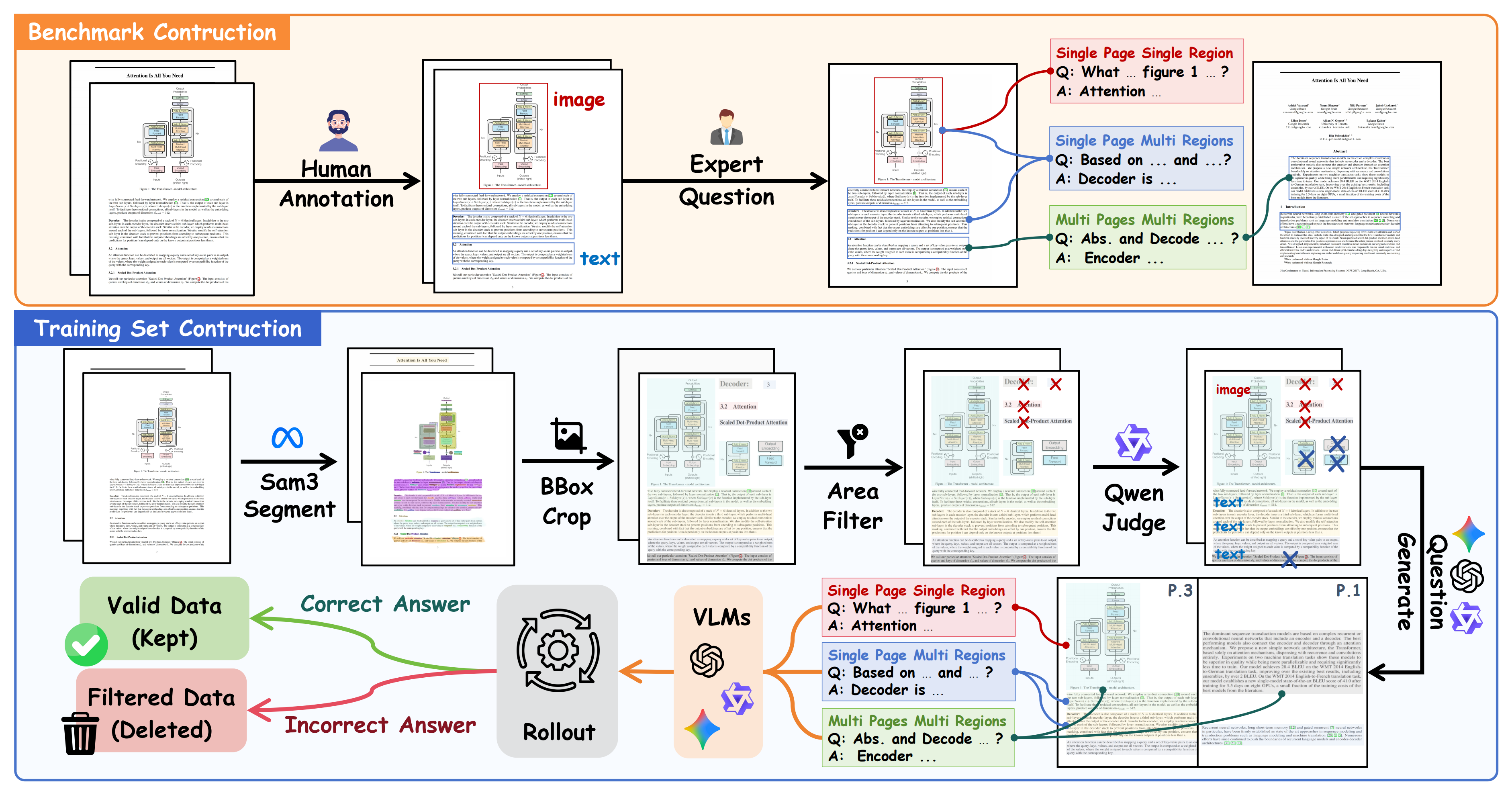
A fine-grained benchmark built from 80 arXiv papers with manual semantic-region annotations for rigorous evaluation of scientific document understanding and evidence grounding.
- 1,623 QA samples
- 1,941 pages
- 80 papers
- Human fine-grained annotated